Why ParSolGen?
Automated Distributed Memory support
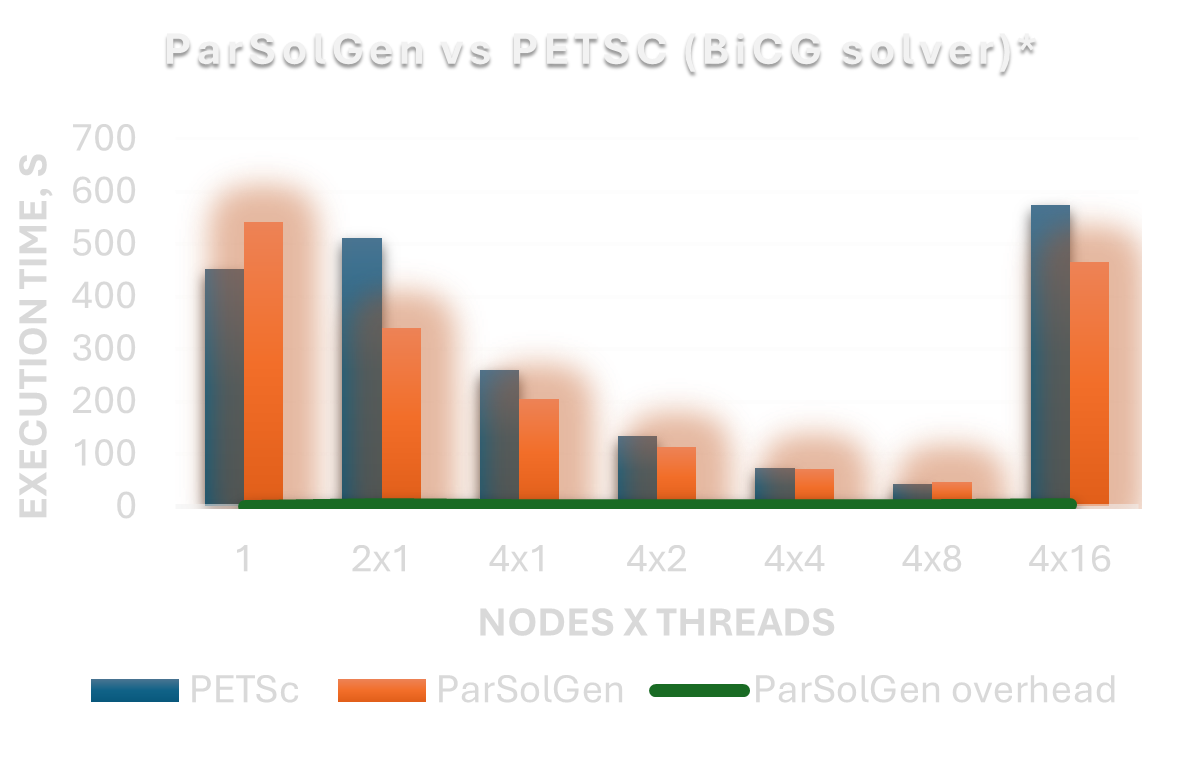
ParSolGen automatically generates a highly-efficient parallel program from the given numerical algorithm description. It automatically handles communication between the nodes of a supercomputer, distributes and balances the load. No manual MPI programming required.

Automated GPU support
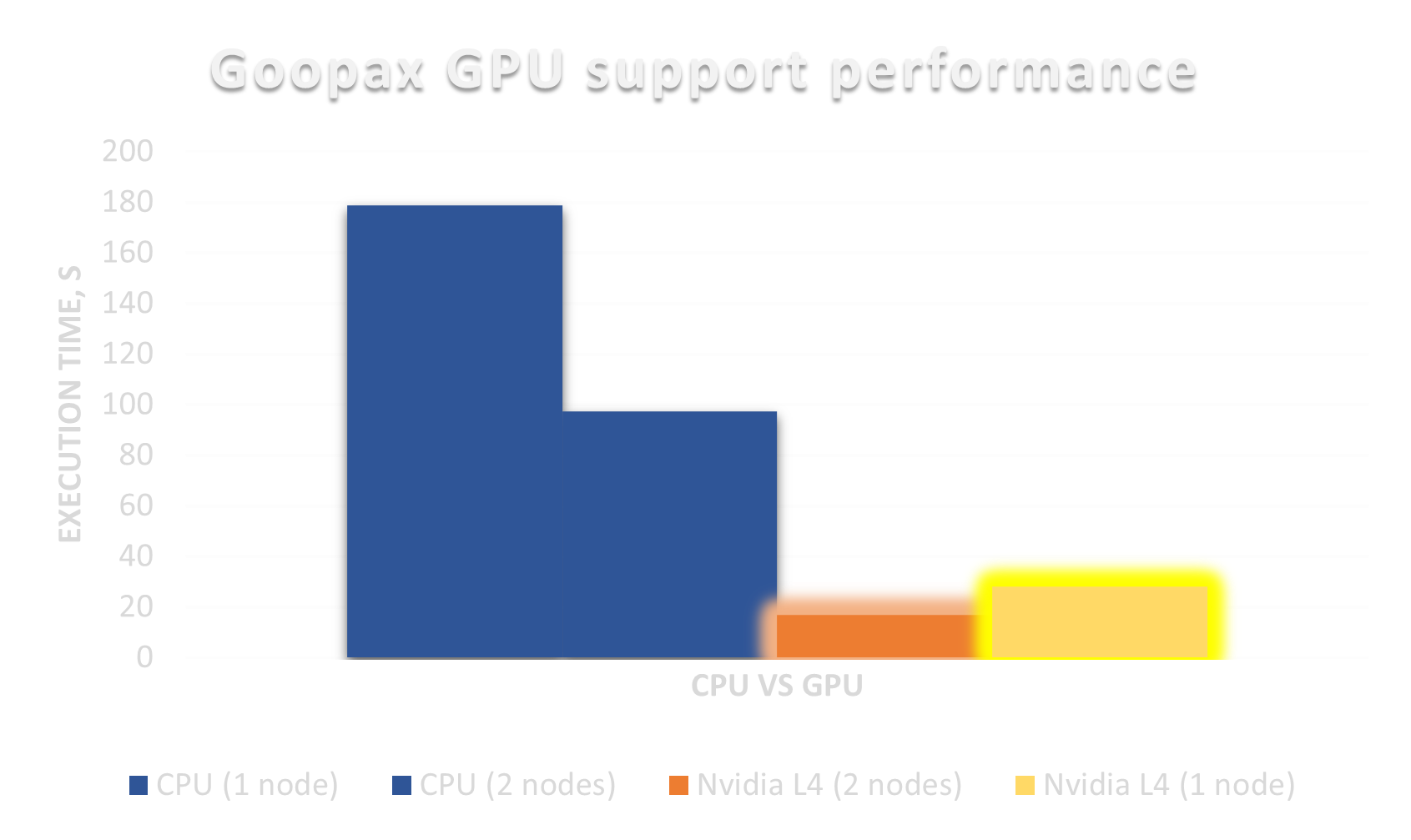
ParSolGen is designed for modern heterogeneous HPC systems combining both CPUs and GPUs. Goopax (https://goopax.com/) allows the automated offload of the work to various GPU-based accelerators. ParSolGen automatically handles the load distribution and data transfer between the host and GPUs.

No more complicated network programming
Communication between the nodes of a supercomputer and between the accelerators installed are handled automatically. No MPI knowledge is required. Generate parallel programs with ParSolGen and compile them with any mpicxx compiler.

Complex information dependencies handling
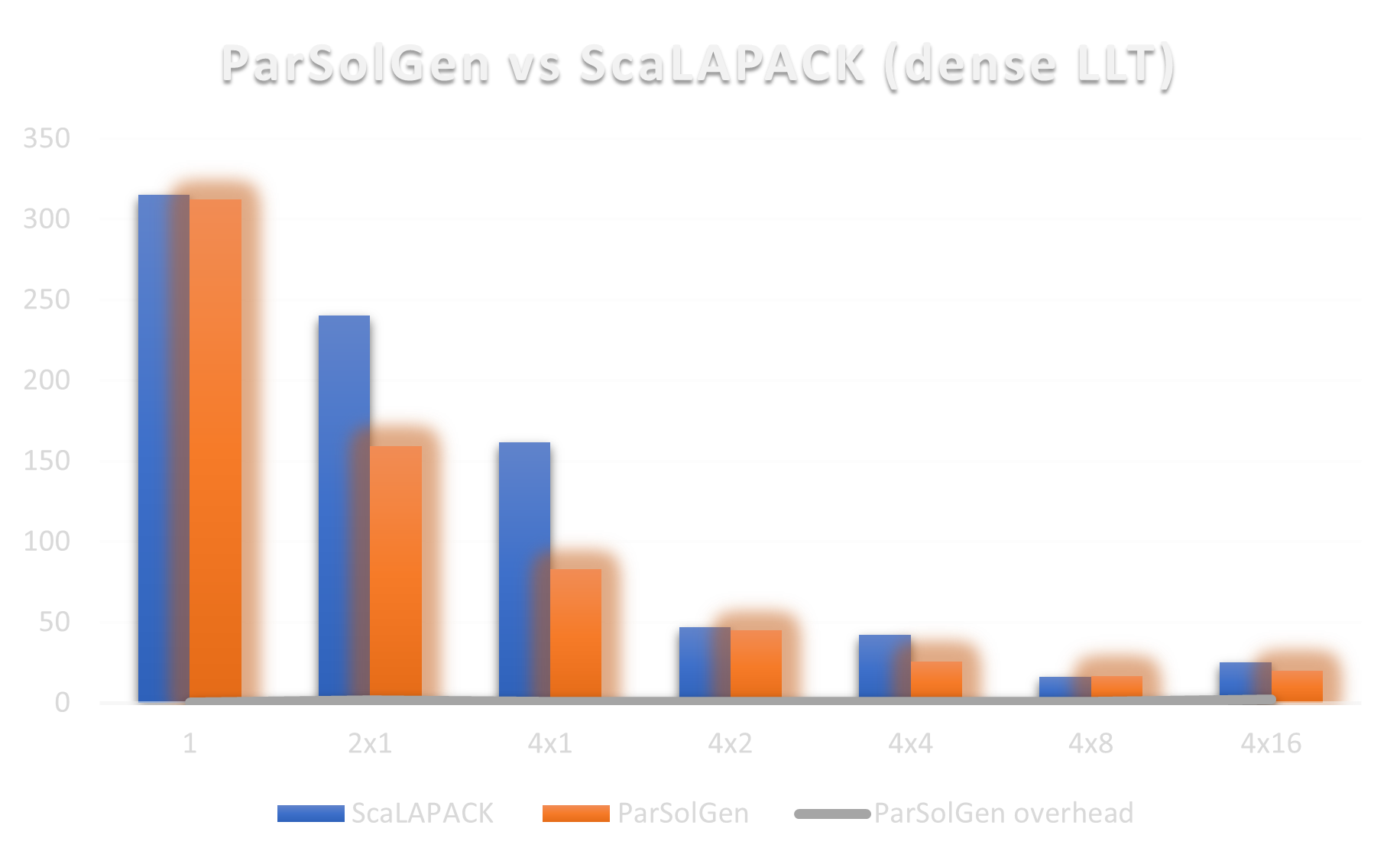
ParSolGen supports various numerical algorithm domains including dense and sparse linear algebra providing high performance of the generated programs.